Premio Marr (Premio al mejor papel) Ganador, ICCV 2011
Devi Parikh y Kristen Grauman
“Who in the rainbow can draw the line where the violet tint ends and the orange tint begins? Distinctly we see the difference of the colors, but where exactly does the one first blendingly enter into the other? So with sanity and insanity.”
— Herman Melville, Billy Budd

Abstracto
Los “atributos” visuales de nombre humano pueden beneficiar varias tareas de reconocimiento. Sin embargo, las técnicas existentes restringen estas propiedades a etiquetas categóricas (por ejemplo, una persona está “sonriendo” o no, una escena es “seca” o no) y, por lo tanto, no capturan relaciones semánticas más generales. Proponemos modelar atributos relativos. Dados los datos de entrenamiento que indican cómo las categorías de objeto / escena se relacionan de acuerdo con diferentes atributos, aprendemos una función de clasificación por atributo. Las funciones de clasificación aprendidas predicen la fuerza relativa de cada propiedad en imágenes nuevas. Luego construimos un modelo generativo sobre el espacio conjunto de salidas de clasificación de atributos, y proponemos una nueva forma de aprendizaje cero en el que el supervisor relaciona la categoría de objeto invisible con objetos previamente vistos mediante atributos (por ejemplo, ‘los osos son más peleteros que las jirafas ‘). Además, mostramos cómo los atributos relativos propuestos permiten descripciones textuales más ricas para nuevas imágenes, que en la práctica son más precisas para la interpretación humana. Demostramos el enfoque en conjuntos de datos de rostros y escenas naturales, y mostramos sus claras ventajas sobre la predicción de atributos binarios tradicionales para estas nuevas tareas.
Motivación
Los atributos binarios son restrictivos y pueden ser antinaturales. En los ejemplos anteriores, si bien uno puede caracterizar la imagen en la parte superior izquierda y en la superior derecha como natural y artificial respectivamente, ¿cómo describiría la imagen en el centro superior como? La única forma significativa de caracterizarlo es con respecto a las otras imágenes: es menos natural que la imagen de la izquierda, pero más que la imagen de la derecha.
Propuesta
En este trabajo, proponemos modelar atributos relativos. A diferencia de predecir la presencia de un atributo, un atributo relativo indica la fuerza de un atributo en una imagen con respecto a otras imágenes. Además de ser más naturales, los atributos relativos ofrecen un modo de comunicación más rico, lo que permite el acceso a una supervisión humana más detallada (y por lo tanto una mayor precisión de reconocimiento), así como la capacidad de generar descripciones más informativas de imágenes novedosas.
Diseñamos un enfoque que aprende una función de clasificación para cada atributo, dadas las restricciones relativas de similitud en pares de ejemplos (o, más generalmente, un ordenamiento parcial en algunos ejemplos). La función de clasificación aprendida puede estimar un rango de valor real para las imágenes que indican la fuerza relativa de la presencia del atributo en ellas.
Introducimos formas novedosas de aprendizaje de disparo cero y descripción de imágenes que explotan las predicciones relativas de los atributos.
Enfoque
Aprendizaje de atributos relativos: cada atributo relativo se aprende a través de una formulación de aprendizaje a rango, dada la supervisión comparativa, como se muestra a continuación:
![]()
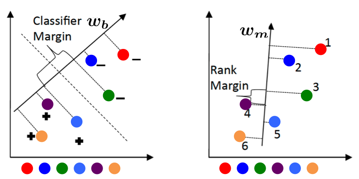
Distinción entre aprender una función de clasificación de margen amplio (derecha) que aplica el orden deseado en los puntos de entrenamiento (1-6) y un clasificador binario de margen amplio (izquierda) que solo separa las dos clases (+ y -), y no necesariamente preservar un orden deseado en los puntos se muestra a continuación:
Nuevo aprendizaje de lanzamiento cero: estudiamos la siguiente configuración
N categorías totales: categorías vistas S (hay imágenes asociadas disponibles) + categorías U no vistas (no hay imágenes disponibles para estas categorías)
Las categorías vistas se describen una con relación a la otra mediante atributos (no todos los pares de categorías deben estar relacionados para todos los atributos)
Las categorías U no vistas se describen en relación con (un subconjunto de) categorías vistas en términos de (un subconjunto de) atributos.
Primero entrenamos un conjunto de atributos relativos utilizando la supervisión provista en las categorías vistas. Estos atributos también pueden ser entrenados previamente a partir de datos externos. Luego construimos un modelo generativo (gaussiano) para cada categoría vista utilizando las respuestas de los atributos relativos a las imágenes de las categorías vistas. Luego inferimos los parámetros de los modelos generativos de caregories invisibles al utilizar sus descripciones relativas con respecto a categorías vistas. A continuación, se muestra una visualización del enfoque simple que empleamos para esto:
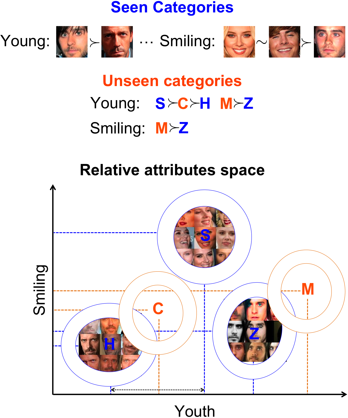
Una imagen de prueba se asigna a la categoría con la máxima verosimilitud.
Generación automática de descripciones textuales relativas de imágenes: dada una imagen que describiré, evaluamos todas las funciones de clasificación aprendidas en I. Para cada atributo, identificamos dos imágenes de referencia situadas a cada lado de I, y no muy lejos o muy cerca a I. La imagen I se describe con relación a estas dos imágenes de referencia, como se muestra a continuación:

Como se vio anteriormente, además de describir una imagen relativa a otras imágenes, nuestro enfoque también puede describir una imagen relativa a otras categorías, lo que da como resultado una descripción puramente textual. Claramente, las descripciones relativas son más precisas e informativas que la descripción binaria convencional.
Experimentos y resultados
Llevamos a cabo experimentos en dos conjuntos de datos:
(1) Reconocimiento de escenas al aire libre (OSR) que contiene 2688 imágenes de 8 categorías: costa C, bosque F, autopista H, ciudad interior I, montaña M, campo abierto O, calle S y edificio alto T. Utilizamos las características generales para representar las imágenes.
(2) Un subconjunto de Public Figures Face Database (PubFig) que contiene 772 imágenes de 8 categorías: Alex Rodríguez A, Clive Owen C, Hugh Laurie H, Jared Leto J, Miley Cyrus M, Scarlett Johansson S, Viggo Mortensen V y Zac Efron Z. Utilizamos las funciones de color y concatenado para representar las imágenes.
La lista de atributos utilizados para cada conjunto de datos, junto con las anotaciones de atributos binarios y relativos se muestran a continuación:
Aprendizaje con cero disparos:
Comparamos nuestro enfoque propuesto con dos líneas de base. El primero es Atributos relativos basados en puntajes (SRA). Esta línea de base es la misma que nuestra aproximación, excepto que usa los puntajes de un clasificador binario (atributos binarios) en lugar de los puntajes de una función de clasificación. Esta línea base ayuda a evaluar la necesidad de una función de clasificación para modelar mejor los atributos relativos. Nuestra segunda línea de base es el modelo de Predicción de Atributo Directo (DAP) introducido por Lampert et al. en CVPR 2009. Esta línea base ayuda a evaluar los beneficios del tratamiento relativo de atributos en lugar de categórico. Evaluamos estos enfoques para diferentes cantidades de categorías no vistas, cantidades variables de datos utilizados para entrenar los atributos, variando el número de atributos utilizados para describir las categorías invisibles, y variando los niveles de ‘soltura’ en la descripción de categorías no vistas. Los detalles de la configuración experimental se pueden encontrar en nuestro documento. Los resultados se muestran a continuación:

Descripciones de imágenes generadas automáticamente:
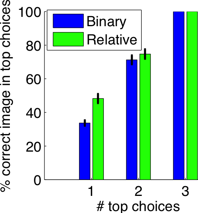
Con el fin de evaluar la calidad de nuestras descripciones de imágenes relativas a las contrapartes binarias, llevamos a cabo un estudio en humanos. Generamos una descripción de una imagen utilizando nuestro enfoque, así como los atributos binarios de la línea base. Presentamos los temas con esta descripción, junto con tres imágenes. Una de las tres imágenes era la imagen que se describe. La tarea de los sujetos era clasificar las tres imágenes en función de cuál creían que era más probable que fuera la que se describía. Cuanto más precisa sea la descripción, mejores serán las probabilidades de que los sujetos identifiquen la imagen correcta. A continuación se muestra una ilustración de una tarea presentada a los sujetos:

Los resultados del estudio se muestran a continuación. Vemos que los sujetos pueden identificar la imagen correcta de forma más precisa utilizando nuestros atributos relativos propuestos, en comparación con los atributos binarios.
Ejemplos de descripciones binarias de imágenes así como descripciones relativas a categorías se muestran a continuación:
| Imagen | Descripciones binarias | Descripciones relativas |
 |
ot natural no abierto perspectiva |
más natural que tallbuilding, menos natural que forest más abierto que alto, menos abierto que la costa más perspectiva que tallbuilding |
 |
no es natural no abierto perspectiva |
más natural que insidecity, menos natural que highway más abierto que la calle, menos abierto que la costa más perspectiva que autopista, menos perspectiva que insidecity |
 |
natural abierto perspectiva |
más natural que tallbuilding, menos natural que montaña más abierto que la montaña menos perspectiva que a campo abierto |
 |
Blanco no sonriendo VisibleForehead |
más blanco que AlexRodriguez más sonriente que JaredLeto, menos sonriente que ZacEfron más VisibleForehead que JaredLeto, menos VisibleForehead que MileyCyrus |
 |
Blanco no sonriendo no visible |
más blanco que Alex Rodríguez, menos blanco que MileyCyrus Menos sonriendo que HughLaurie más VisibleForehead que ZacEfron, menos VisibleForehead que MileyCyrus |
 |
no joven Cejas espesas Cara redonda |
más joven que CliveOwen, menos joven que ScarlettJohansson más BushyEyebrows que ZacEfron, menos BushyEyebrows que AlexRodriguez más RoundFace que CliveOwen, menos RoundFace que ZacEfron |
Datos
Proporcionamos los atributos relativos aprendidos y sus predicciones para los dos conjuntos de datos utilizados en nuestro documento: reconocimiento de escena al aire libre (OSR) y un subconjunto de la base de datos de caras públicas (PubFig).
Dataset relativo de atributos de cara. Contiene anotaciones para 29 atributos relativos en 60 categorías de Public Figures Face Database (PubFig).
Código
Modificamos la implementación RankSVM de Olivier Chappelle para entrenar atributos relativos con restricciones de similitud. Nuestro código modificado se puede encontrar aquí.
Si usa nuestro código, cite el siguiente documento:
D. Parikh y K. Grauman
Atributos relativos
Conferencia Internacional sobre Visión por Computadora (ICCV), 2011.
Población
Demos de diversas aplicaciones de atributos relativos se pueden encontrar aquí. Una descripción de estas aplicaciones se puede encontrar en los documentos aquí.
Link to original source: https://www.cc.gatech.edu/~parikh/relative.html